


{kind=link}
A common problem in Machine Learning (ML) is choosing a suitable loss function for the task at hand. Often, a task falls into one of two categories: classification or regression. However, there are some problems that do not fit well into either category, which can be illustrated using the following example.
Consider the problem of historical image ranking, where the goal is to accurately predict the decade in which the image was taken. Here, the labels are given in discrete classes, for example, “the 1950s” or “the 1960s”, so it might look like a classification problem at first. Nevertheless, there is also an ordinal structure of the labels. We can place the decades on a timeline, and therefore this problem fits into the category of ordinal regression.




In our paper “Deep Ordinal Regression with Label Diversity”, we show that it is possible to tackle these kinds of problems using a standard classification loss function, while still exploiting the ordinal information of the labels. We do this by introducing the concept of label diversity.
A single label is not enough
Label diversity can be introduced by creating several labels for each training example in a way that the ordinal structure allows. In the problem of estimating age from a single image, where the task is to predict the age of a person, the ground truth values are often given as years in an integer format. So, in one sense, the classes are discrete. A common method used for age estimation in ML is regression with classification (RvC). This is where each year is treated as a separate class, and then a standard cross-entropy loss is used to train the neural network to classify each person. This approach is illustrated in figure 1, where the real number line has been discretized into non-overlapping classes, representing the different age categories.
![]()
Figure 1: A baseline RvC approach to discretization
The drawback of RvC is that the loss is agnostic to the magnitude of the error. An error of 10 years yield the same loss as an error of 1 year, because the ordinal information in the labels is discarded. Intuitively, it would be more advantageous to incorporate this information into the learning process, to get better future predictions.
Generating diversity
In our paper, we show that if we create several sets of overlapping classes, we can achieve the desired property of the loss function. For example, a person that is 40 years old can be labeled in several brackets, such as. 38-42, 39-43, and so on. This representation is in a sense diverse, as each training example is assigned multiple labels. The width of the brackets and the total number of labels for each example are hyperparameters that can be tuned to a specific problem. Figure 2 illustrates the general approach, where the real number line has been discretized in three different ways. During training time, the neural network must learn to correctly classify each example using all labels simultaneously. Therefore, the loss is smaller for a prediction that is closer to the true age of the person.
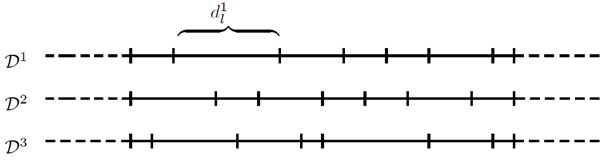
Figure 2: Label diversity can be induced by using multiple discretization’s.
By using label diversity, we can achieve a lower prediction error compared to using the standard RvC method. The results on image ranking are shown in Figure 3, and we see that label diversity yields both higher accuracy and a lower mean average error compared to both direct regression and RvC. In our full paper, we present results on two additional tasks: age estimation and head pose estimation.
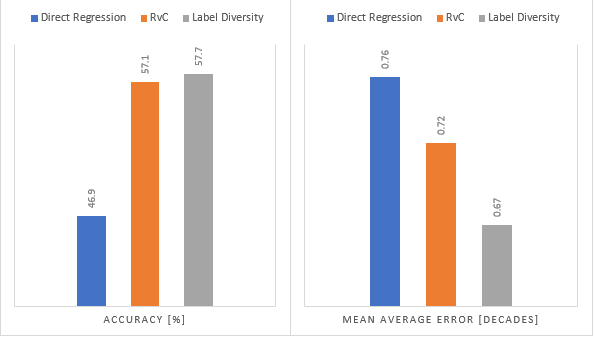
Figure 3: Accuracy and mean average error of the different methods on the Historical Color Images Dataset
How to implement it
Our approach can be used as a simple extension to any neural network by using multiple prediction heads. As illustrated in figure 4, each head is classifying the image into its own set of brackets. Although this method is closely related to ensemble learning, we can train all prediction heads simultaneously as they share backbone feature extractor. Therefore, the computational overhead is minimal at both training and inference time, which is important for mobile applications.
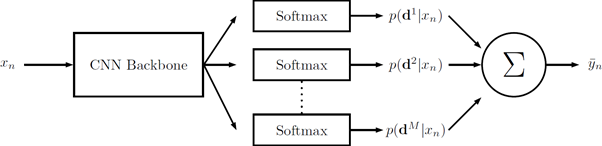
Figure 4: A feature extractor is trained using multiple prediction heads. At inference time, the different outputs are combined into a single prediction.
Label diversity could also be used for a wide range of other problems where the ordinal label structure is important. For example, there are many medical applications, such as cancer severity grading, where the goal is to make a risk assessment based on screening data. In such applications, the accuracy of the model is critical. However, if you want to run inference on a mobile device, then latency might be more important. Our method allows the used to trade off accuracy and computational resources to tailor it towards the specific use case by varying the degree of diversity.
