


{kind=link}
Courtesy: Rahul Unnikrishnan Nair | Intel
The landscape of AI and natural language processing has dramatically shifted with the advent of Large Language Models (LLMs). This shift is characterized by advancements like Low-Rank Adaptation (LoRA) and its more advanced iteration, Quantized LoRA (QLoRA), which have transformed the fine-tuning process from a compute-intensive task into an efficient, scalable procedure.




Generated with Stable Diffusion XL using the prompt: “A cute laughing llama with big eyelashes, sitting on a beach with sunglasses reading in gibili style”
The Advent of LoRA: A Paradigm Shift in LLM Fine-Tuning
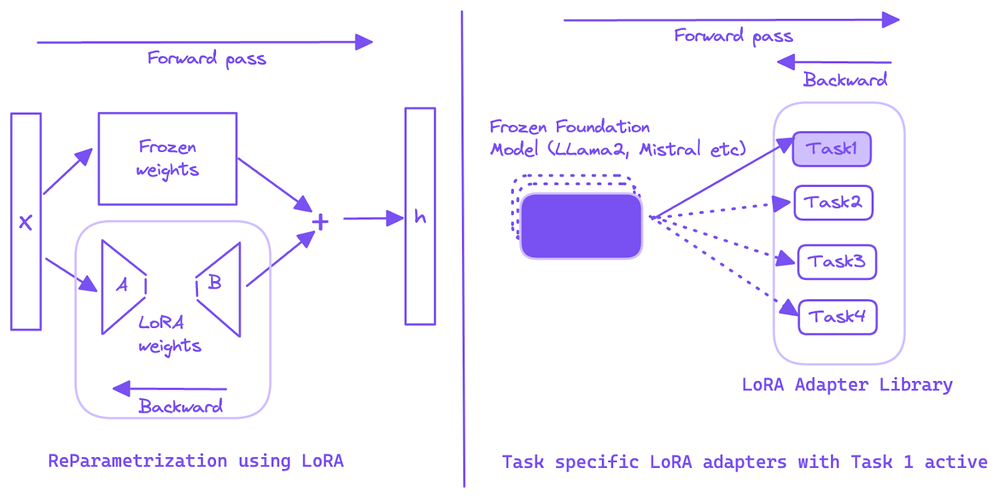
LoRA represents a significant advancement in the fine-tuning of LLMs. By introducing trainable adapter modules between the layers of a large pre-trained model, LoRA focuses on refining a smaller subset of model parameters. These adapters are low-rank matrices, significantly reducing the computational burden and preserving the valuable pre-trained knowledge embedded within LLMs. The key aspects of LoRA include:
- Low-Rank Matrix Structure: Shaped as (r x d), where ‘r’ is a small rank hyperparameter and ‘d’ is the hidden dimension size. This structure ensures fewer trainable parameters.
- Factorization: The adapter matrix is factorized into two smaller matrices, enhancing the model’s function adaptability with fewer parameters.
- Scalability and Adaptability: LoRA balances the model’s learning capacity and generalizability by scaling adapters with a parameter α and incorporating dropout for regularization.
Quantized LoRA (QLoRA): Efficient Finetuning on Intel Hardware
QLoRA advances LoRA by introducing weight quantization, further reducing memory usage. This approach enables the fine-tuning of large models, such as the 70B LLama2, on hardware like Intel’s Data Center GPU Max Series 1100 with 48 GB VRAM. QLoRA’s main features include:
- Memory Efficiency: Through weight quantization, QLoRA substantially reduces the model’s memory footprint, crucial for handling large LLMs.
- Precision in Training: QLoRA maintains high accuracy, crucial for the effectiveness of fine-tuned models.
- On-the-Fly Dequantization: It involves temporary dequantization of quantized weights for computations, focusing only on adapter gradients during training.
Fine-Tuning Process with QLoRA on Intel Hardware
The fine-tuning process starts with setting up the environment and installing necessary packages, including bigdl-llm for model loading, peft for LoRA adapters, Intel Extension for PyTorch for training using Intel dGPUs, transformers for finetuning and datasets for loading the dataset. We will walk through the high-level process of fine-tuning a large language model (LLM) to improve its capabilities. As an example, I am taking generating SQL queries from natural language input, but the focus is on general QLoRA finetuning here. For detailed explanations you can check out the full notebook that takes you from setting up the required python packages, loading the model, finetuning and inferencing the finetuned LLM to generate SQL from text on Intel Developer Cloud and also here.
Model Loading and Configuration for Fine-Tuning
The foundational model is loaded in a 4-bit format using bigdl-llm, significantly reducing memory usage. This step is crucial for fine-tuning large models like the 70B LLama2 on Intel hardware.
from bigdl.llm.transformers import AutoModelForCausalLM
# Loading the model in a 4-bit format for efficient memory usage
model = AutoModelForCausalLM.from_pretrained(
“model_id”, # Replace with your model ID
load_in_low_bit=”nf4″,
optimize_model=False,
torch_dtype=torch.float16,
modules_to_not_convert=[“lm_head”],
)
Learning Rate and Stability in Training
Selecting an optimal learning rate is critical in QLoRA fine-tuning to balance training stability and convergence speed. This decision is vital for effective fine-tuning outcomes as a higher learning rate can lead to instabilities and the training loss to abnormally drop to zero after a few steps.
from transformers import TrainingArguments
# Configuration for training
training_args = TrainingArguments(
learning_rate=2e-5, # Optimal starting point; adjust as needed
per_device_train_batch_size=4,
max_steps=200,
# Additional parameters…
)
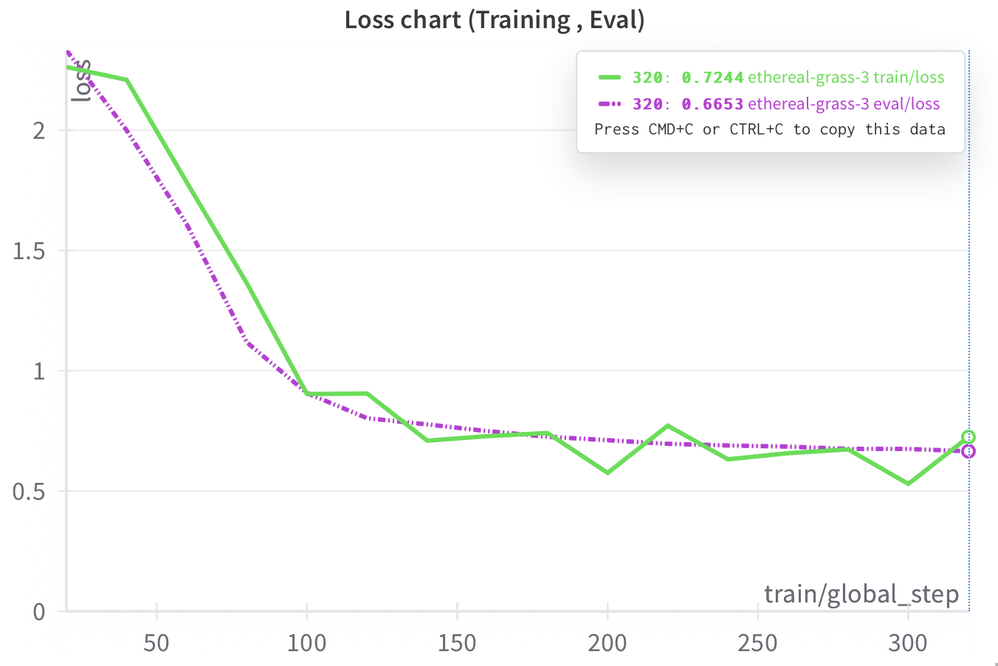
During the fine-tuning process, there is a notable rapid decrease in the loss after just a few steps, which then gradually levels off, reaching a value near 0.6 at approximately 300 steps as seen in the graph below:
Text-to-SQL Conversion: Prompt Engineering
With the fine-tuned model, we can convert natural language queries into SQL commands, a vital capability in data analytics and business intelligence. To finetune the model, we must carefully convert the data into structured prompt like below as an instruction dataset with Input, Context and Response:
# Function to generate structured prompts for Text-to-SQL tasks
def generate_prompt_sql(input_question, context, output=””):
return f”””You are a powerful text-to-SQL model. Your job is to answer questions about a database. You are given a question and context regarding one or more tables.
You must output the SQL query that answers the question.
### Input:
{input_question}
### Context:
{context}
### Response:
{output}”””
Diverse Model Options
The notebook supports an array of models, each offering unique capabilities for different fine-tuning objectives:
NousResearch/Nous-Hermes-Llama-2-7b
NousResearch/Llama-2-7b-chat-hf
NousResearch/Llama-2-13b-hf
NousResearch/CodeLlama-7b-hf
Phind/Phind-CodeLlama-34B-v2
openlm-research/open_llama_3b_v2
openlm-research/open_llama_13b
HuggingFaceH4/zephyr-7b-beta
Enhanced Inference with QLoRA: A Comparative Approach
The true test of any fine-tuning process lies in its inference capabilities. In the case of the implementation, the inference stage not only demonstrates the model’s proficiency in task-specific applications but also allows for a comparative analysis between the base and the fine-tuned models. This comparison sheds light on the effectiveness of the LoRA adapters in enhancing the model’s performance for specific tasks.
Model Loading for Inference:
For inference, the model is loaded in a low-bit format, typically 4-bit, using bigdl-llm library. This approach drastically reduces the memory footprint, making it suitable to run multiple LLMs with high parameter count on a single resource-optimized hardware like Intel’s Data Center GPUs 1100. The following code snippet illustrates the model loading process for inference:
from bigdl.llm.transformers import AutoModelForCausalLM
# Loading the model for inference
model_for_inference = AutoModelForCausalLM.from_pretrained(
“finetuned_model_path”, # Path to the fine-tuned model
load_in_4bit=True, # 4 bit loading
optimize_model=True,
use_cache=True,
torch_dtype=torch.float16,
modules_to_not_convert=[“lm_head”],
)
Running Inference: Comparing Base vs Fine-Tuned Model
Once the model is loaded, we can perform inference to generate SQL queries from natural language inputs. This process can be conducted on both the base model and the fine-tuned model, allowing users to directly compare the outcomes and assess the improvements brought about by fine-tuning with QLoRA:
# Generating a SQL query from a text prompt
text_prompt = generate_sql_prompt(…)
# Base Model Inference
base_model_sql = base_model.generate(text_prompt)
print(“Base Model SQL:”, base_model_sql)
# Fine-Tuned Model Inference
finetuned_model_sql = finetuned_model.generate(text_prompt)
print(“Fine-Tuned Model SQL:”, finetuned_model_sql)
Following a 15-minute training session itself, the finetuned model demonstrates enhanced proficiency in generating SQL queries that more accurately reflect the given questions, compared to the base model. With additional training steps, we can anticipate further improvements in the model’s response accuracy:
Finetuned model SQL generation for a given question and context:
Base model SQL generation for a given question and context:
LoRA Adapters: A Library of Task-Specific Enhancements
One of the most compelling aspects of LoRA is its ability to act as a library of task-specific enhancements. These adapters can be fine-tuned for distinct tasks and then saved. Depending on the requirement, a specific adapter can be loaded and used with the base model, effectively switching the model’s capabilities to suit different tasks. This adaptability makes LoRA a highly versatile tool in the realm of LLM fine-tuning.
Checkout the notebook on Intel Developer Cloud
We invite AI practitioners and developers to explore the full notebook on the Intel Developer Cloud (IDC). IDC is the perfect environment to experiment with and explore the capabilities of fine-tuning LLMs using QLoRA on Intel hardware. Once you login to Intel Developer Cloud, go to the “Training Catalog” and under “Gen AI Essentials” in the catalog, you can find the LLM finetuning notebook.
Conclusion: QLoRA’s Impact and Future Prospects
QLoRA, especially when implemented on Intel’s advanced hardware, represents a significant leap in LLM fine-tuning. It opens up new avenues for leveraging massive models in various applications, making fine-tuning more accessible and efficient.