


 and similar stats, measuring AI performance requires new metrics.){kind=link}
Courtesy: Nvidia
What is a token? Why is batch size important? And how do they help determine how fast AI computes?
The era of the AI PC is here, and it’s powered by NVIDIA RTX and GeForce RTX technologies. With it comes a new way to evaluate performance for AI-accelerated tasks, and a new language that can be daunting to decipher when choosing between the desktops and laptops available.




While PC gamers understand frames per second (FPS) and similar stats, measuring AI performance requires new metrics.
Coming Out on TOPS
The first baseline is TOPS, or trillions of operations per second. Trillions is the important word here — the processing numbers behind generative AI tasks are absolutely massive. Think of TOPS as a raw performance metric, similar to an engine’s horsepower rating. More is better.
Compare, for example, the recently announced Copilot+ PC lineup by Microsoft, which includes neural processing units (NPUs) able to perform upwards of 40 TOPS. Performing 40 TOPS is sufficient for some light AI-assisted tasks, like asking a local chatbot where yesterday’s notes are.
But many generative AI tasks are more demanding. NVIDIA RTX and GeForce RTX GPUs deliver unprecedented performance across all generative tasks — the GeForce RTX 4090 GPU offers more than 1,300 TOPS. This is the kind of horsepower needed to handle AI-assisted digital content creation, AI super resolution in PC gaming, generating images from text or video, querying local large language models (LLMs) and more.
Insert Tokens to Play
TOPS is only the beginning of the story. LLM performance is measured in the number of tokens generated by the model.
Tokens are the output of the LLM. A token can be a word in a sentence, or even a smaller fragment like punctuation or whitespace. Performance for AI-accelerated tasks can be measured in “tokens per second.”
Another important factor is batch size, or the number of inputs processed simultaneously in a single inference pass. As an LLM will sit at the core of many modern AI systems, the ability to handle multiple inputs (e.g. from a single application or across multiple applications) will be a key differentiator. While larger batch sizes improve performance for concurrent inputs, they also require more memory, especially when combined with larger models.
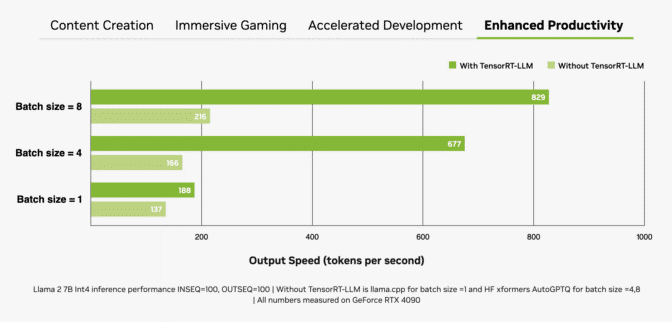
The more you batch, the more (time) you save.
RTX GPUs are exceptionally well-suited for LLMs due to their large amounts of dedicated video random access memory (VRAM), Tensor Cores and TensorRT-LLM software.
GeForce RTX GPUs offer up to 24GB of high-speed VRAM, and NVIDIA RTX GPUs up to 48GB, which can handle larger models and enable higher batch sizes. RTX GPUs also take advantage of Tensor Cores — dedicated AI accelerators that dramatically speed up the computationally intensive operations required for deep learning and generative AI models. That maximum performance is easily accessed when an application uses the NVIDIA TensorRT software development kit (SDK), which unlocks the highest-performance generative AI on the more than 100 million Windows PCs and workstations powered by RTX GPUs.
The combination of memory, dedicated AI accelerators and optimized software gives RTX GPUs massive throughput gains, especially as batch sizes increase.
Text-to-Image, Faster Than Ever
Measuring image generation speed is another way to evaluate performance. One of the most straightforward ways uses Stable Diffusion, a popular image-based AI model that allows users to easily convert text descriptions into complex visual representations.
With Stable Diffusion, users can quickly create and refine images from text prompts to achieve their desired output. When using an RTX GPU, these results can be generated faster than processing the AI model on a CPU or NPU.
That performance is even higher when using the TensorRT extension for the popular Automatic1111 interface. RTX users can generate images from prompts up to 2x faster with the SDXL Base checkpoint — significantly streamlining Stable Diffusion workflows.
ComfyUI, another popular Stable Diffusion user interface, added TensorRT acceleration last week. RTX users can now generate images from prompts up to 60% faster, and can even convert these images to videos using Stable Video Diffuson up to 70% faster with TensorRT.
TensorRT acceleration can be put to the test in the new UL Procyon AI Image Generation benchmark, which delivers speedups of 50% on a GeForce RTX 4080 SUPER GPU compared with the fastest non-TensorRT implementation.
TensorRT acceleration will soon be released for Stable Diffusion 3 — Stability AI’s new, highly anticipated text-to-image model — boosting performance by 50%. Plus, the new TensorRT-Model Optimizer enables accelerating performance even further. This results in a 70% speedup compared with the non-TensorRT implementation, along with a 50% reduction in memory consumption.
Of course, seeing is believing — the true test is in the real-world use case of iterating on an original prompt. Users can refine image generation by tweaking prompts significantly faster on RTX GPUs, taking seconds per iteration compared with minutes on a Macbook Pro M3 Max. Plus, users get both speed and security with everything remaining private when running locally on an RTX-powered PC or workstation.
The Results Are in and Open Sourced
But don’t just take our word for it. The team of AI researchers and engineers behind the open-source Jan.ai recently integrated TensorRT-LLM into its local chatbot app, then tested these optimizations for themselves.
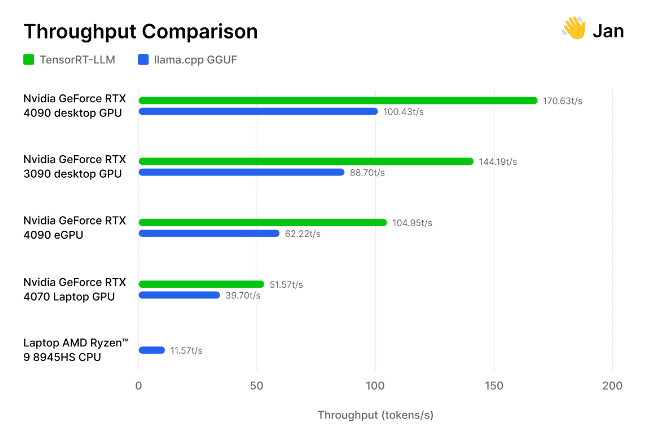
The researchers tested its implementation of TensorRT-LLM against the open-source llama.cpp inference engine across a variety of GPUs and CPUs used by the community. They found that TensorRT is “30-70% faster than llama.cpp on the same hardware,” as well as more efficient on consecutive processing runs. The team also included its methodology, inviting others to measure generative AI performance for themselves.
From games to generative AI, speed wins. TOPS, images per second, tokens per second and batch size are all considerations when determining performance champs.