


{kind=link}
Ethernet has long been the leading technology for networking and is universally used in Data Centers, Service Provider, and Enterprise Networks. InfiniBand technology has been used in high performance computing (HPC) applications because of the low unloaded latency required for specific HPC applications. AI/ML training clusters require very high bandwidth and reliable transport with predictable low tail latency to reduce job completion time. As described below, for the same switch bandwidth and SerDes speed, Ethernet has comparable performance to InfiniBand (IB) for AI/ML training jobs. The Ethernet ecosystem provides significant advantages in bandwidth, SerDes speeds, multi-vendor standard solutions, cost, power (economics), throughput, and performance versus InfiniBand solutions.
With the recent explosion of AI/ML applications, AI/ML training models and jobs are increasing dramatically in size. A typical backend AI/ML cluster network consists of hundreds to thousands of AI/ML accelerators, CPUs, NVMe storage devices, one or two tiers of network switches, and Network Interface Cards (NICs) connected to the GPU or a PCIe Switch. Some GPUs have NIC functionality integrated as well.




AI/ML cluster networks should be evaluated on the following key characteristics:
Bandwidth and speeds
As the training jobs are becoming larger, it is essential to have higher radix switches and higher port speeds for building large training clusters with flat topologies.
Performance
Flow completion time is a critical metric for AI/ML training performance. Lower flow completion times defined by P99.9% are typically used.
Two essential capabilities to achieve lower job completion times are a) effective load balancing to achieve high network utilization and b) congestion control mechanisms to achieve predictable tail latency.
Management
Operational ease of use and configuration is vital. Integration with existing infrastructure management makes operations seamless.
Power
Lower power for the overall solution of cluster size is critical.
Telemetry
Network fabric capabilities to troubleshoot link failures, anomalies, link utilization, packet size distribution, traffic monitoring (IPFix/SFlow).
Ethernet vs. IB comparison
Bandwidth and speeds: An IB switch with a bandwidth of 25.6T was recently announced. In contrast, Broadcom began mass production of Tomahawk 4, the world’s first 25.6Tb/s switch, in 2020. This Ethernet switch chip has been deployed in hyperscale data centers worldwide for compute, storage, and AI/ML cluster connectivity. Table 1 shows the Ethernet switch availability in the market.
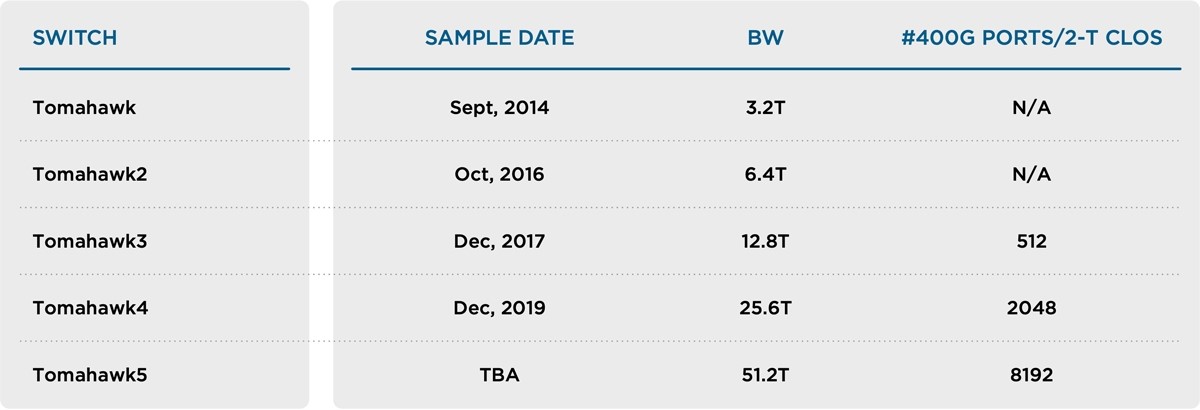
Table 1: Ethernet Switch Availability
Broadcom’s Tomahawk switches have doubled in bandwidth roughly every two years. The increased radix of switches allows for a larger cluster size in a 2-tier Clos.
Performance
Broadcom’s Ethernet switches support several mechanisms for Load Balancing:
- ECMP and Weighted ECMP
- Dynamic Load Balancing
- Perfect Load Balancing
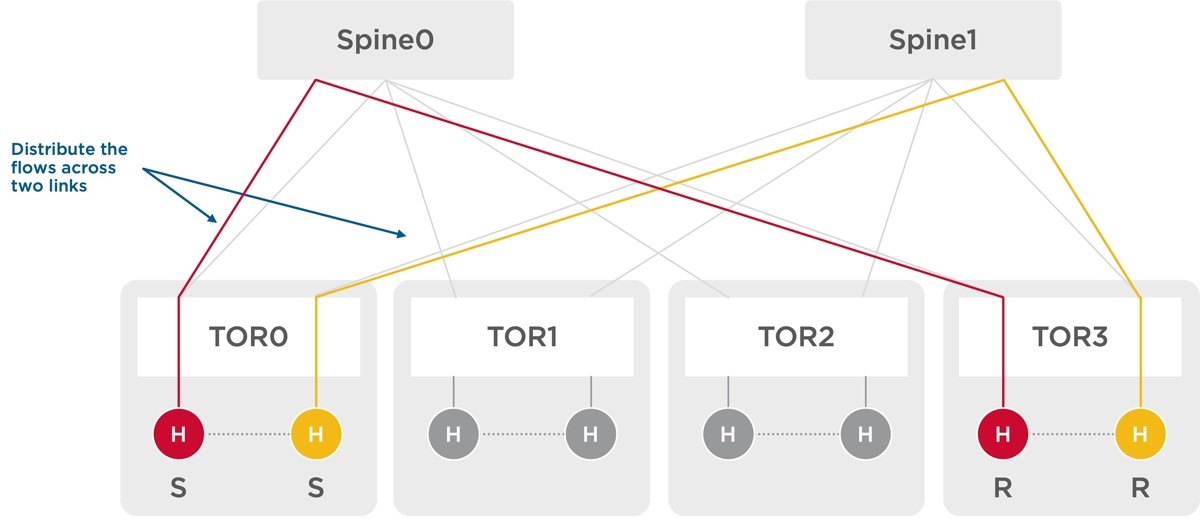
Figure 1: Load Balancing across links
The Tomahawk line of switches has extensive support for ECMP/WCMP and Dynamic Load Balancing, distributing flows among links based on the dynamic load. Packet order is still maintained. Adaptive Routing is also supported to avoid congestion hotspots in the network.
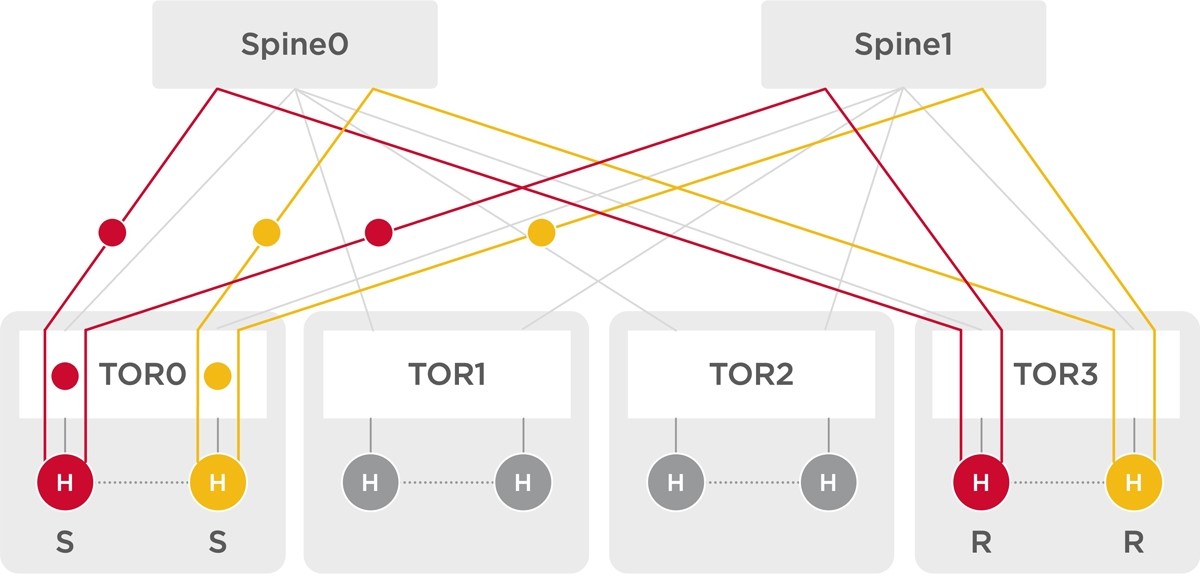
Figure 2: Perfect Load Balancing in DNX Fabric
The DNX family of switches and fabric devices support Perfect Load Balancing independent of the hashing scheme. Packets are split into cells; cells are sprayed across all the available paths and reassembled at the destination switch. The DNX fabric achieves the lowest tail latency due to its perfect load balance at a very high network load. In addition, the DNX fabric provides a) end-to-end Credit Protocol for congestion avoidance (compared to reactive congestion control in IB), b) hardware-based link failure detection and rerouting, c) lower power using its most efficient cell switch chips, and d) large clusters in a single traffic and management domain
Performance comparison between Ethernet and IB:
AI training is a network-intensive application and needs a network infrastructure with high bandwidth and low tail latency. In their paper, Erickson et al. [1] compare the performance of RoCE vs. IB with 100Gb Ethernet and 100G EDR. Directly connected latency and directly connected bandwidth were metrics that were used. As shown in Figure 3 reproduced below, the latency of the IB and Ethernet-based RoCE systems is virtually identical.
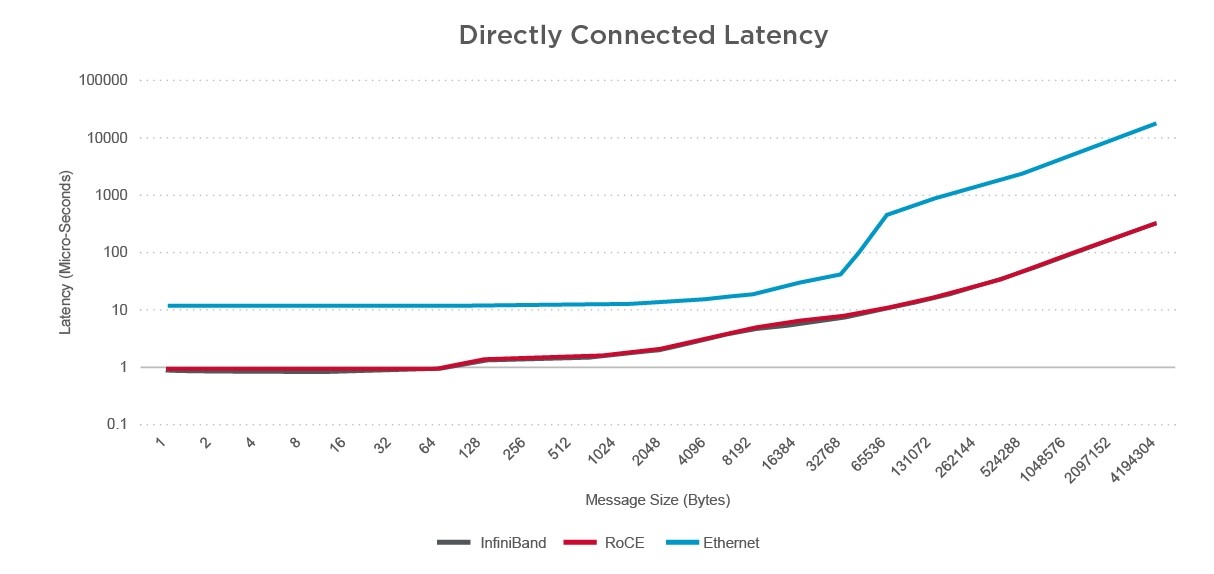
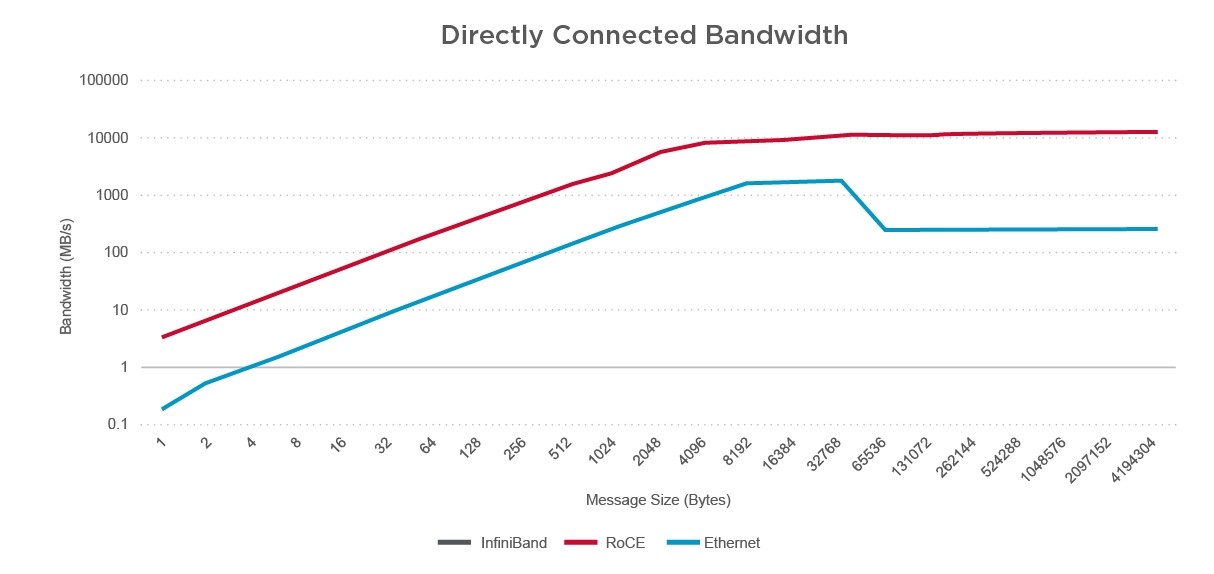
Figure 3: Directly Connected Latency and Directly Connected Bandwidth comparison of RoCE vs. IB (Reproduced figures from [1]) Erickson, L. Kachelmeier, F. Vig, “Comparison of High-Performance Network Options: EDR Infiniband vs. 100Gb RDMA Capable Ethernet
In testing performed by a large hyperscale cloud operator, a two-tier topology was used to compare the performance of IB and Ethernet switches, as shown in Figure 4.
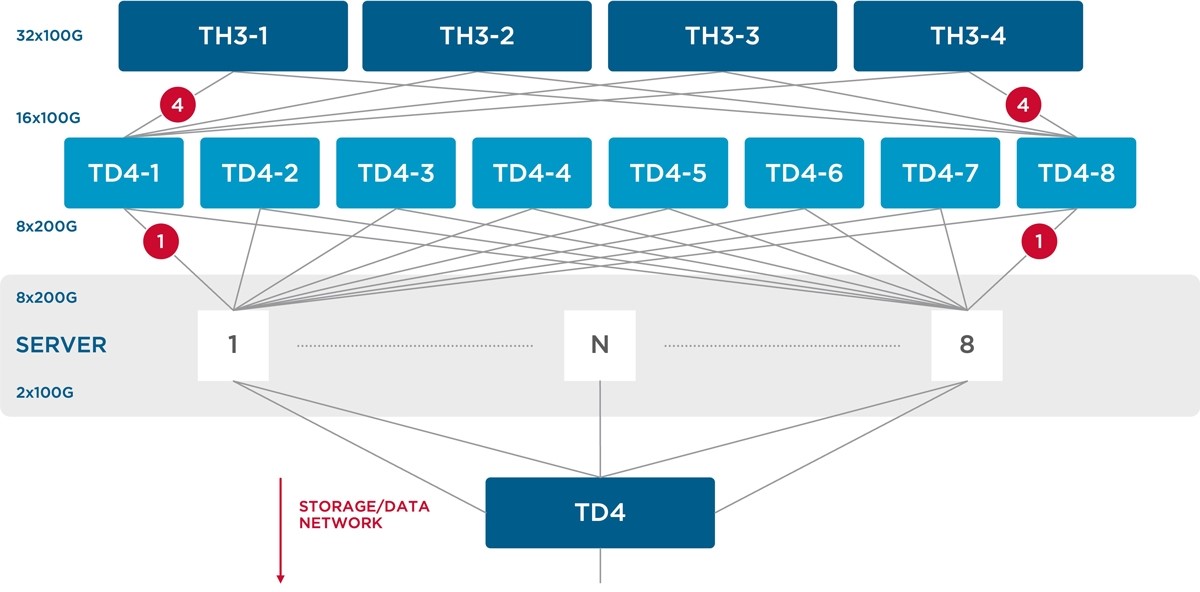
Figure 4: Two-tier test setup to connect 64 GPUs
The test setup included standard Trident4 and Tomahawk3 switches to connect 64 GPUs.
In this testing, the NCCL library was used to run benchmarks on the GPUs. This testbed was used to run the benchmark of AllReduce and All-to-All collectives, which are important for AI/ML applications. Figure 4 below shows the average latency comparison between IB and Ethernet for these collectives.
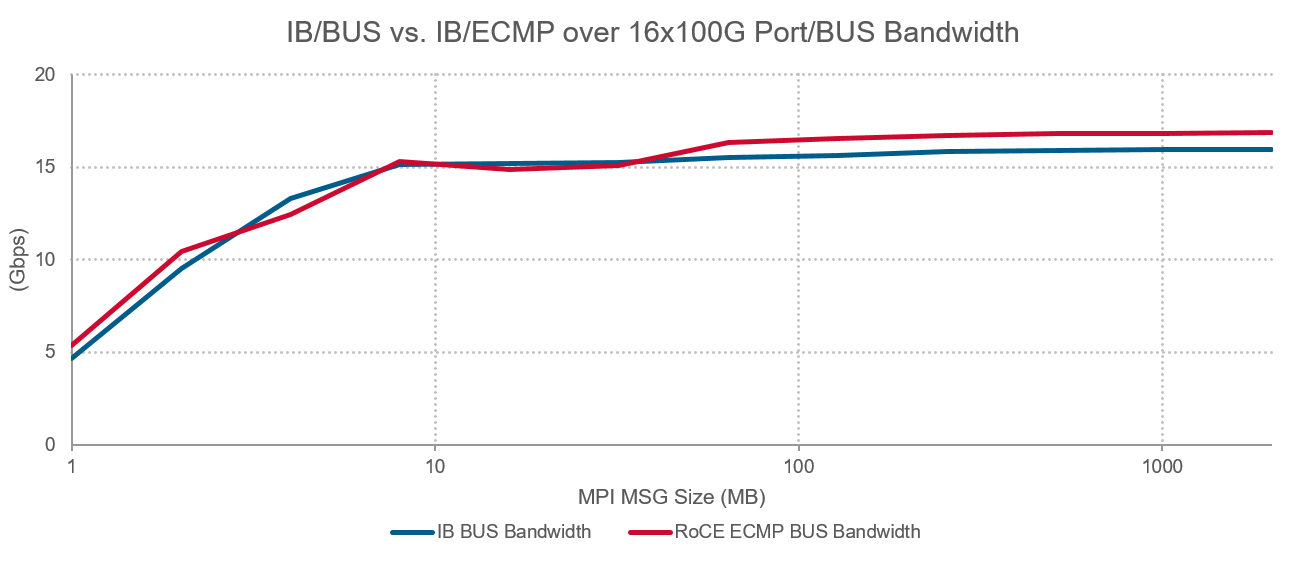
Figure 5: NCCL test throughput comparison: Ethernet vs. IB
The results show that Ethernet throughput was approximately 4% better than IB for most message sizes. The AI/ML training workloads typically have larger message sizes for which Ethernet provides better performance. It is worth noting that Trident/Tomahawk setting were kept at default settings, and major optimizations such as the use of 400G (instead of 100G) links between TOR and Spine were not implemented. Despite this, the Trident/Tomahawk network still showed performance improvement over optimized IB network.
Table 2 below shows a comparison between Ethernet and IB across various attributes.
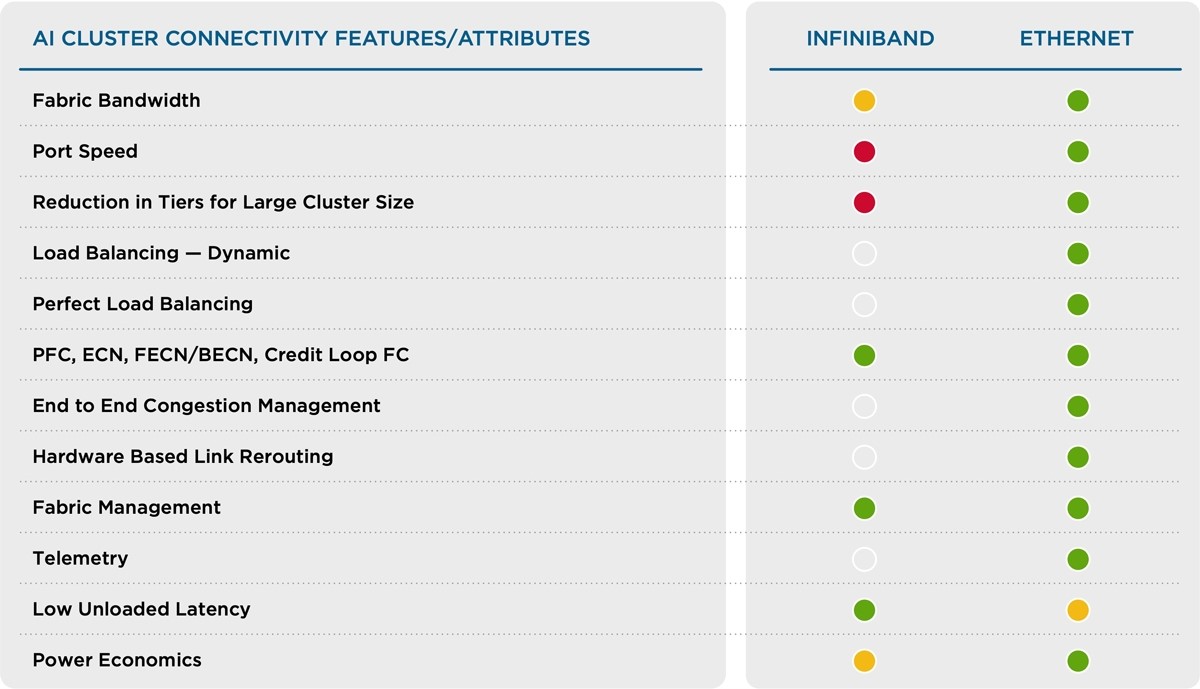
Table 2: Ethernet vs. IB: Comparative Metrics
Based on customer testimonials and internal testing, the flow completion time for AI/ML workloads on DNX and Tomahawk switches is comparable to IB switch fabrics. Furthermore, with the DNX devices, the tail latency is lower because of end-to-end congestion management and perfect load balancing in the network.
Ethernet has all the necessary attributes for a high-performance AI/ML training cluster: high bandwidth, end-to-end congestion management, load balancing, fabric management, and better economics than InfiniBand. Ethernet has a rich ecosystem with multiple silicon vendors, OEMs, ODMs, a software ecosystem, and a healthy pace of innovations. Broadcom’s switches are deployed in AI/ML training clusters and are tunable for the AI/ML application performance.
